Label 缓存模式
前言
根据实际应用场景设置 Label 的 Cache Mode 属性,可以有效的优化 Label 绘制,减少 Drawcall。
# 一. 缓存类型
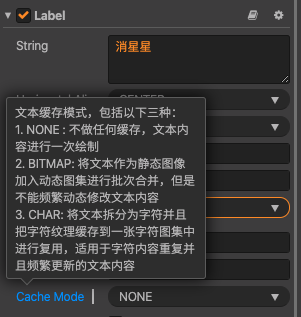
# 1. NONE:
默认值,会将 Label 中的整段文本将生成一张位图, 但是并不参与动态合图。
不做任何缓存,文本内容进行一次绘制。
# 2. BITMAP:
『 将文本作为静态图像加入动态图集进行批次合并,但是不能频繁动态修改文本内容 』。
选择后,Label 中的整段文本仍将生成一张位图,但是会尽量参与 动态合图。只要满足动态合图的要求,就会和动态合图中的其它 Sprite 或者 Label 合并 Draw Call。由于动态合图会占用更多内存,该模式只能用于文本不常更新的 Label。
和 NONE 模式一样,BITMAP 模式会强制给每个 Label 组件生成一张位图,不论文本内容是否等同。如果场景中有大量相同文本的 Label,建议使用 CHAR 模式以复用内存空间。
# 3. CHAR:
原理类似 BMFont,Label 将以“字”为单位将文本缓存到全局共享的位图中,相同字体样式和字号的每个字符将在全局共享一份缓存。能支持文本的频繁修改,对性能和内存最友好。
不过目前该模式还存在如下限制,我们将在后续的版本中进行优化:
- 该模式只能用于字体样式和字号固定(通过记录字体的 fontSize、fontFamily、color、outline 为关键信息,以此进行字符的重复使用,其他有使用特殊自定义文本格式的需要注意),并且不会频繁出现巨量未使用过的字符的 Label。这是为了节约缓存,因为全局共享的位图尺寸为 2048*2048,只有场景切换时才会清除,一旦位图被占满后新出现的字符将无法渲染。
- 不能参与动态合图(同样启用 CHAR 模式的多个 Label 在渲染顺序不被打断的情况下仍然能合并 Draw Call)
# 风险:
字符图集的大小是受限的,总大小只有2048*2048。这里带来的风险是,不能无限制地使用 CHAR 模式来显示文字,因为有可能在图集重建之前把图集用完,用完的结果将导致后续使用 CHAR 模式的 Label 无法再正常显示文字,因为新的字符无法再往这张唯一的图集中继续添加了。
# 4. 注意:
- Cache Mode 对所有平台都有优化效果。
- BITMAP 模式取代了原先的
Batch As Bitmap选项,旧项目如启用了Batch As Bitmap将自动迁移至该选项。 - 使用缓存模式时不能剔除 项目 -> 项目设置 -> 模块设置 面板中的
RenderTexture模块。
# 5. 总结:
| Cache Mode | 文本图片 | 最佳实践 |
|---|---|---|
| NONE | 单个 Label 使用一张节点大小的图片 | 适用频繁更新的不定文本,如:聊天功能 |
| BITMAP | 文本修改需要重绘,绘制后添加到 2048x2048 的通用动态图集中 | 适用内容不会改变的静态文本,如:界面标题 |
| CHAR | 每个字符绘制一次并添加到 2048x2048 的字符图集中 | 适用频繁更新且文本字符内容有限的文本,如:分数、倒计时等 |
# 二. CHAR 无限模式
『 在唯一的一张图集上重复利用 』。
这个思路的难点有如下几个:
- 如何判断某个字符已经是废弃状态?
- 如何快速找到一个可被重复利用的合适的字符在图集中的位置?
- 如果找不到一个合适的可重复利用的字符,还有没有可利用的新的图集空间容纳新的字符?
# 1. 难点分析
# a. 如何判断某个字符已经是废弃状态?
文字图集上的每个字符可以用字典记录下它的位置和大小信息,还有一个是被引用的次数。
判断废弃的状态,可以通过对这个字符的引用次数来决定,例如一个 CHAR 模式的文本"abcaddae"渲染时,a字符的引用次数是3,b是1,c是1,d是2,e是1,那么文本被移除时,减除相应的引用计数即可。当某个字符的引用计数为0时,即代表它所占的图集位置是个废弃的状态,可以被回收再利用。
# b. 如何快速找到一个可被重复利用的合适的字符在图集中的位置?
在第一点里面,我们创建的字符和图集位置的映射里面,有位置信息和大小信息。先筛选废弃状态再通过大小判断是不能容纳新的字符即可找到可重复利用的目标字符位置。
# c. 如果找不到一个合适的可重复利用的字符,还有没有可利用的新的图集空间容纳新的字符?
这个问题比较好解决,我们在 2048*2048 的图集上,拿出一部分空间作为保留空间先不使用。
查找空间时,先查找非保留空间是不有合适位置,再查找是不有可重复利用的废弃空间。如果还没有,再到保留空间里面来添加新字符。
当然有人会说,如果保留空间也被使用完了怎么办?这个优化方案可以拉到文末查看。
# 三. 无限模式解决方案
这里,我们以获取字符图集的接口 getLetterDefinitionForChar(letter-font.js)为突破口,这个接口是用来查找并添加新的字符,新的查找思路如下:
# 1. 查询字是否存在
是否已经在当前 this._fontDefDictionary._letterDefinitions 中存在?
存在则直接返回。这是当前的流程中已经有的,保留即可!
# 2. 查找图集安全区
当前字符图集的安全区是否有足够空间插入新的字符?
足够则执行添加新字符的流程。在 LetterAtlas 中添加字段 _safeHeight 用于保存当前安全区的图集高度:即 2048 的高度中有多少是可以随意添加字符集的,这里直接乘以自己设定的比例即可。
具体的查找过程是:
# a. 计算新添加的字符的显示高度与宽度:
通过 textUtils.safeMeasureText 来计算。
# b. 在图集的当前游标位置添加新的字符是否能成功?
宽度超过 2048,或高度超过 _safeHeight 都算失败:
canInsertLabel(labelInfo, char, force) {
let sizeArr = LetterTexture.calcTextSize(labelInfo,char);
let width = sizeArr[0];
let height = sizeArr[1];
let nextY = this._nexty;
let thisY = this._y;
if ((this._x + width + space) > this._width) {
thisY = this._nexty;
}
if ((thisY + height) > nextY) {
nextY = thisY + height + space;
}
let maxY = force ? this._height : this._safeHeight;
if (nextY > maxY) {
return false;
}
return true;
}
# c. 能够添加,则走当前的插入新字符的流程:
let _insertNewLetter = function () {
let temp = new LetterTexture(char, labelInfo);
temp.updateRenderData();
let _letter = self.insertLetterTexture(temp);
_letter.char = char;
temp.destory();
return _letter;
}
# 3. 在废弃的字符统计中查找合适的字符大小
在废弃的字符统计中查找合适的字符大小,如果能找到,则执行废弃字符再复用流程。
在 letter-font.js 中添加字段:let _unusedLetterList = [];
用于收集已经废弃的字符数组。数组里面存储的是 FontLetterDefinition 对象。当然 FontLetterDefinition 对象也需要新加几个字段:
// 字符宽高用于后续被重新复用时判断是否能容纳下新的字符
letter.originW = letterTexture._width;
letter.originH = letterTexture._height;
// hash值是这个TTF字符的唯一标识,由颜色,字号,字体,描边等信息组成
letter.hash = letterTexture._hash;
// 引用计数用于统计当前字符被引用的次数,判断是否是废弃状态
letter.refCount = 0;
# 查找方法 findUnsedLetterFor(char) 的逻辑是:
- 判断数组
_unusedLetterList是否为空,如果为空则返回 null; - 逐个判断废弃字符的
originW,originH是否 >= 当前新字符。(后期优化查找效率和命中率的位置就在这里); - 找到则返回当前的
FontLetterDefinition对象,否则返回n ull。
如果 findUnsedLetterFor 的返回值不为 null,则可以直接调用 replaceLetterTexture 方法在废弃字符的位置上画上新的字符。
replaceLetterTexture(oldLetter, lerrerTexture, char) {
let oldHash = oldLetter.hash;
let texture = lerrerTexture._texture;
this._fontDefDictionary._texture.drawTextureAt(texture, oldLetter.u-bleed/2, oldLetter.v-bleed/2);
oldLetter.hash = lerrerTexture._hash;
oldLetter.w = lerrerTexture._width - bleed;
oldLetter.h = lerrerTexture._height - bleed;
oldLetter.offsetY = lerrerTexture._offsetY;
oldLetter.refCount = 0;
this._dirty = true;
this._fontDefDictionary.addLetterDefinitions(lerrerTexture._hash, oldLetter);
this._fontDefDictionary._letterDefinitions[oldHash] = null;
return oldLetter;
},
# 4. 在保留区域内判断是否有足够空间添加新字符
在保留区域内判断是否有足够空间添加新字符,如果有,则执行插入流程。
如果执行到这一步,说明新插入的字符大号比较大,前面显示的字符中都未出现过。那么就需要尝试在保留区域内去插入新的字符,这里和前面在安全区内插入字符是同样的过程,不同的是 canInsertLabel 接口的 force 参数传入 true 即可在保留区域内去搜索图集位置。
# 5. 否则报错!
经过以上所有步骤都无法找到合适的图集时,就要报错提醒了。
← 脚本组件生命周期 Label 获取高度 →